LeNet-5, from the paper Gradient-Based Learning Applied to Document Recognition, is a very efficient convolutional neural network for handwritten character recognition.
The LeNet-5 architecture consists of two sets of convolutional and average pooling layers, followed by a flattening convolutional layer, then two fully-connected layers and finally a softmax classifier.
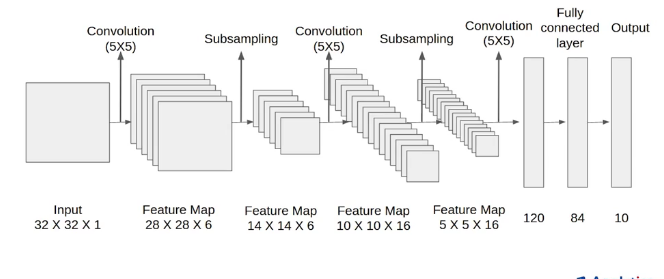
The first is the data INPUT layer. The size of the input image is uniformly normalized to 32 * 32.
Note: This layer does not count as the network structure of LeNet-5. Traditionally, the input layer is not considered as one of the network hierarchy.
Input picture: 32 * 32
Convolution kernel size: 5 * 5
Convolution kernel types: 6
Output featuremap size: 28 * 28 (32-5 + 1) = 28
Number of neurons: 28 * 28 * 6
Trainable parameters: (5 * 5 + 1) * 6 (5 * 5 = 25 unit parameters and one bias parameter per filter, a total of 6 filters)
Number of connections: (5 * 5 + 1) * 6 * 28 * 28 = 122304
Input: 28 * 28
Sampling area: 2 * 2
Sampling method: 4 inputs are added, multiplied by a trainable parameter, plus a trainable offset. Results via sigmoid
Sampling type: 6
Output featureMap size: 14 * 14 (28/2)
Number of neurons: 14 * 14 * 6
Trainable parameters: 2 * 6 (the weight of the sum + the offset)
Number of connections: (2 * 2 + 1) * 6 * 14 * 14
Input: all 6 or several feature map combinations in S2
Convolution kernel size: 5 * 5
Convolution kernel type: 16
Output featureMap size: 10 * 10 (14-5 + 1) = 10
Each feature map in C3 is connected to all 6 or several feature maps in S2, indicating that the feature map of this layer is a different combination of the feature maps extracted from the previous layer.
One way is that the first 6 feature maps of C3 take 3 adjacent feature map subsets in S2 as input. The next 6 feature maps take 4 subsets of neighboring feature maps in S2 as input. The next three take the non-adjacent 4 feature map subsets as input. The last one takes all the feature maps in S2 as input.
The trainable parameters are: 6 * (3 * 5 * 5 + 1) + 6 * (4 * 5 * 5 + 1) + 3 * (4 * 5 * 5 + 1) + 1 * (6 * 5 * 5 +1) = 1516
Number of connections: 10 * 10 * 1516 = 151600
Input: 10 * 10
Sampling area: 2 * 2
Sampling method: 4 inputs are added, multiplied by a trainable parameter, plus a trainable offset. Results via sigmoid
Sampling type: 16
Output featureMap size: 5 * 5 (10/2)
Number of neurons: 5 * 5 * 16 = 400
Trainable parameters: 2 * 16 = 32 (the weight of the sum + the offset)
Number of connections: 16 * (2 * 2 + 1) * 5 * 5 = 2000
Input: All 16 unit feature maps of the S4 layer (all connected to s4)
Convolution kernel size: 5 * 5
Convolution kernel type: 120
Output featureMap size: 1 * 1 (5-5 + 1)
Trainable parameters / connection: 120 * (16 * 5 * 5 + 1) = 48120
Input: c5 120-dimensional vector
Calculation method: calculate the dot product between the input vector and the weight vector, plus an offset, and the result is output through the sigmoid function.
Trainable parameters: 84 * (120 + 1) = 10164
